

Ни для кого не секрет, что рынок приложений для изучения языков переполнен. Казалось бы, ничего нового здесь придумать уже нельзя, а конкуренция так огромна, что соперничать с устоявшимися лидерами бессмысленно и лучше уйти в разработку в других направлениях. Однако если мыслить стратегически и следить за тенденциями можно найти лазейку и создать приложение, которое “выстрелит” в этой сфере. Как это сделать, от каких критериев стоит отталкиваться и на что обращать самое пристальное внимание? Своим опытом делится эксперт в области разработки мобильных приложений Илья Задябин.
Эпоха глобализма подталкивает людей к изучению языков: если человек стремится к саморазвитию и профессиональному росту, он, как правило, не хочет ограничивать себя предложениями о работе лишь в одном языковом пространстве. Закономерно, что просто найти подходящую зарубежную вакансию недостаточно, стать претендентом на нее можно лишь владея соответствующим языком. И лучше чтобы освоение иностранного не было задачей, решаемой на протяжении нескольких лет. А поскольку традиционные методы обучения не могут похвастаться скоростью передачи знаний и успешного ими овладения, новое слово в разработке на этом направлении сказать все еще можно. Рассмотрим, чему стоит уделить внимание, если эта идея вам близка.
Тенденции рынка в помощь
Сегодня уже не откроешь никому Америку, если скажешь, что на помощь в любом деле, связанном с массивами информации, может прийти искусственный интеллект. Однако всего несколько лет назад это не было так очевидно. Чтобы найти успешную идею для проекта и понять, как грамотно применить то, что уже лежит у вас под носом, нужно следить за тенденциями рынка разработки в целом, а не только узкого сектора создания именно языковых приложений. Так, в 2021 году, когда создавалось приложение Slai (Self Learning Artificial Intelligence), про возможности ИИ уже было многое известно, но к миру изучения языков его еще активно не применяли. И обратить внимание на способности ИИ к переводу и задуматься о постановке ИИ на службу обучения языкам — было шагом в сторону того самого нового слова, которое все стремятся найти, чтобы оказаться на гребне волны.
В случае приложения для изучения языков ответ на вопрос “Зачем здесь ИИ?” лежит на поверхности — грамотно написанный бот может имитировать общение с носителем языка, которое незаменимо для успешного обучения. Это как частный репетитор, но без необходимости заботиться о расписании да еще и с адаптацией под потребности и уровень каждого ученика.
Помимо удобства для пользователя, подобные приложения в целом преобразуют мир изучения иностранных языков, делая его доступным для людей даже в странах с низким уровнем дохода. И по этим причинам именно здесь сегодня сосредоточено основное внимание разработчиков.
Процесс разработки: с нуля до реализации
Процесс создания приложения состоит из ряда шагов, некоторые из которых могут оказаться неочевидными. И не менее важна их последовательность. Рассмотрим их подробнее.
Шаг 1. Поиск оптимальной модели приложения через анализ ЦА
Никто не расскажет лучше, чего не хватает на рынке, чем пользователи. К поиску оптимальной модели будет максимально целесообразно подключить вашу целевую аудиторию и постараться понять, какие у них есть дефициты, какие их потребности еще не закрыты и с какими трудностями они сталкиваются при использовании того, что уже доступно.
Стоит спрашивать не только про опыт использования приложений именно в выбранной вами области, но и в смежных — это даст возможность посмотреть на проблему более широко. Так, мы спрашивали на интервью не только про изучение языков, но и про курсы программирования, SMM, дизайна, садоводства — искали, что в целом “цепляет” людей, заинтересованных в саморазвитии, а также анализировали благодаря этому, насколько сложным должно быть обучение.
На выходе на стыке всей собранной информации получается довольно четкая картина незакрытых потребностей, от которых можно отталкиваться и двигаться дальше.
Шаг 2. Анализ конкурентов и отстройка от них

Если ваш сектор рынка перенасыщен и в нем есть яркие лидеры, закономерно, что нет смысла пытаться их обогнать. Нужно идти другим путем, предлагая что-либо полезное пользователю из того, что он еще не получил. К примеру, задумавшись о разработке еще одного языкового приложения, первым делом мы смотрели на список топов в этой сфере и анализировали их конкурентные преимущества и недостатки: Praktika, Memrise, Falou. Также в лист анализа было включено приложение Replika. Оно не направлено на обучение языку, но это самый популярный чат-бот с ИИ, разработанный для психологической поддержки. Безусловно, это не сфера обучения, но благодаря анализу этого приложения мы поняли, как лучше всего подать общение с ИИ.
По результатам анализа было понятно, что нет смысла биться с условным duolingo за долю рынка, которая достигает 67.8%. По этой причине мы решили позиционировать себя как дополнение к популярным приложениям по изучению языка, играя на их недостатках, о которых мы узнали от пользователей.
В случае с duolingo это недостаток практики в свободном разговоре и письме, а давно существующие сервисы по типу italki отлично развивают разговорные навыки, предоставляя общение с носителями, но в них не хватает структуры и персонализации.
Программы же, направленные на развитие разговорного английского, не так широко распространены, как те, которые сосредоточены на грамматике и лексике. Самые крупные приложения, ориентированные на практику английского языка — HelloTalk, Marq, Andychatbot. Однако в Marq нет возможности поговорить с ботом, а бот, используемый в Andy, невысокого качества. Эти приложения могут содержать чаты, которые учат студентов грамматическим правилам, но не дают им возможности вести реальный разговор.
Существующие разговорные боты можно разделить на две категории: те, которые предназначены для общения, и те, которые предназначены для выполнения конкретных задач. Многие крупные компании в мире обычно ориентируются на последнюю категорию (например, Siri, Ok-Google, Cortana и т.д.). Существуют также разработки, направленные на имитацию диалога между людьми — Replika, Parlai (Facebook), GPT-3 (OpenAi), DialoGPT (Microsoft). По сравнению с ботами, похожими на Siri, они имеют более высокий потенциал.
Шаг 3. Выделение и фиксация продающей идеи
После анализа ЦА и конкурентов на основе его результатов необходимо определиться с продающей идеей. В нашем случае она была сформулирована следующим образом: создать инструмент, который будет доступен каждому, независимо от уровня дохода и места проживания.
Шаг 4. Привлечение необходимых специалистов и поиск СТО
Когда продающая идея всем понятна, дальнейший процесс разработки логичным образом начинает от нее отталкиваться и подстраиваться под ее реализацию. Становится понятно, каких именно специалистов вам необходимо привлечь под проект, помимо стандартного набора разработчиков. В образовательном проекте, в первую очередь, это методисты — без них лучше ничего даже не начинать, будет полный хаос. А так, как наша идея была заточена под привлечение ИИ в процесс обучения, то нам потребовались еще и специалисты в области искусственного интеллекта.
И, разумеется, необходимо определить СТО, или технического директора, который будет руководить всем процессом разработки, а также product-менеджера, который будет налаживать связи с бизнес-инкубаторами, обеспечивая тем самым поддержку приложения с точки зрения его продвижения, и организовывать сustdev для поиска новых идей.
Шаг 5. Создание алгоритма
Процессом создания алгоритма также управляет продающая идея. Стремитесь к удобству и прогрессу каждого ученика? Нужен алгоритм, который сможет адаптироваться под индивидуальные потребности пользователя. Ключевым моментом в разработке в нашем случае было использование искусственного интеллекта для обеспечения интерактивного и персонализированного подхода к обучению. Важно, разумеется, и качество обучения — ведь задача подобного приложения не только в создании условий для общения, но и в коррекции допускаемых учеником ошибок. Для реализации обеих целей в основу проекта было положено машинное обучение, представленное двумя независимыми архитектурами: одна из них может общаться с пользователем, а другая — исправлять его ошибки.
Стоит отметить, что можно нехило споткнуться и затормозить впоследствии релиз приложения, если пытаться охватить необъятное. В нашем случае мы очень много времени потратили на релиз первой версии из-за рассинхронизации веба, ios и android, ведь баги и недочеты были уникальные на разных платформах. Впоследствии мы перешли на кросс-платформенное решение Flutter, чтобы сконцентрировать усилия всех инженеров в одной точке. Мораль в том, нужно перенимать лучшие практики стартапов, а именно: первый релиз только на iOS, дальше собираем обратную связь, метрики, и если всё успешно, то только тогда расширяться на другие платформы.
В какой-то момент мы решили воспользоваться open source решением Gector, для более точной работы модели. После этого мы смогли сосредоточиться на пояснении к ошибкам и более персонализированному анализу каждого пользователя.
Для поддержки нескольких языков мы использовали IBM Watson, а процесс перевода текста выглядел достаточно просто:

Модель была написана на Python и для её более эффективной работы мы решили воспользоваться возможностями NVIDIA GPUs через CUDA. PyTorch предоставляет интерфейс для работы с CUDA, который мы запускали в начале работы модели.

В данном случае под названием большой и маленькой модели прячутся модели facebook: blender_400Mdistill и blender90M. При наличии возможностей CUDA мы могли тестировать гораздо бОльшую модель.
Совет стартаперам: ищите программы помощи стартапам. Например, мы так получили бесплатные мощности IBM. Такие есть почти у каждой современной компании в разделе pricing.
Вам наверняка пригодятся дев версия апи и обычная, чтобы не сломать ничего пользователям, которые уже пользуются приложением, и спокойно тестировать новые возможности на сервере для разработчиков.
В основе нашего бэкенда в docker_compose.yaml запускались несколько сервисов:
- api и api_dev: отвечали за работу endpoints
- worker1, worker2, … worker5 — каждый из которых поднимал у себя blender модель
- worker — зависил от api и всех остальных workers
- Копия worker для dev окружения: dev_worker
Каждый worker состоит из chat_agent и error_agent. Идея с 6-ю worker’ами появилась, чтобы равномерно распределить нагрузку на сервер.
Одной из главных функций приложения была возможность просмотреть обучающие карточки для ошибок. Для реализации этого функционал у нас были размечены различные правила английского языка. Например, для модальных глаголов:
can could may might must shall should will would
Мы добавили пояснение:
Modal verbs are followed by an infinitive without to.
You should go to the doctor.
They can play the piano.
You must come early.
И так почти ко всем правилам. При помощи модели Gector и Bert мы тренировали веса для более точного сопоставления найденных ошибок и наших презаписанных правил английского. Таким образом каждый worker состоял из двух агентов, где один из них предсказывал ошибки.
В функции проверки ошибок мы загружаем модальные глаголы

Далее мы проверяем ключевые слова от Gector:
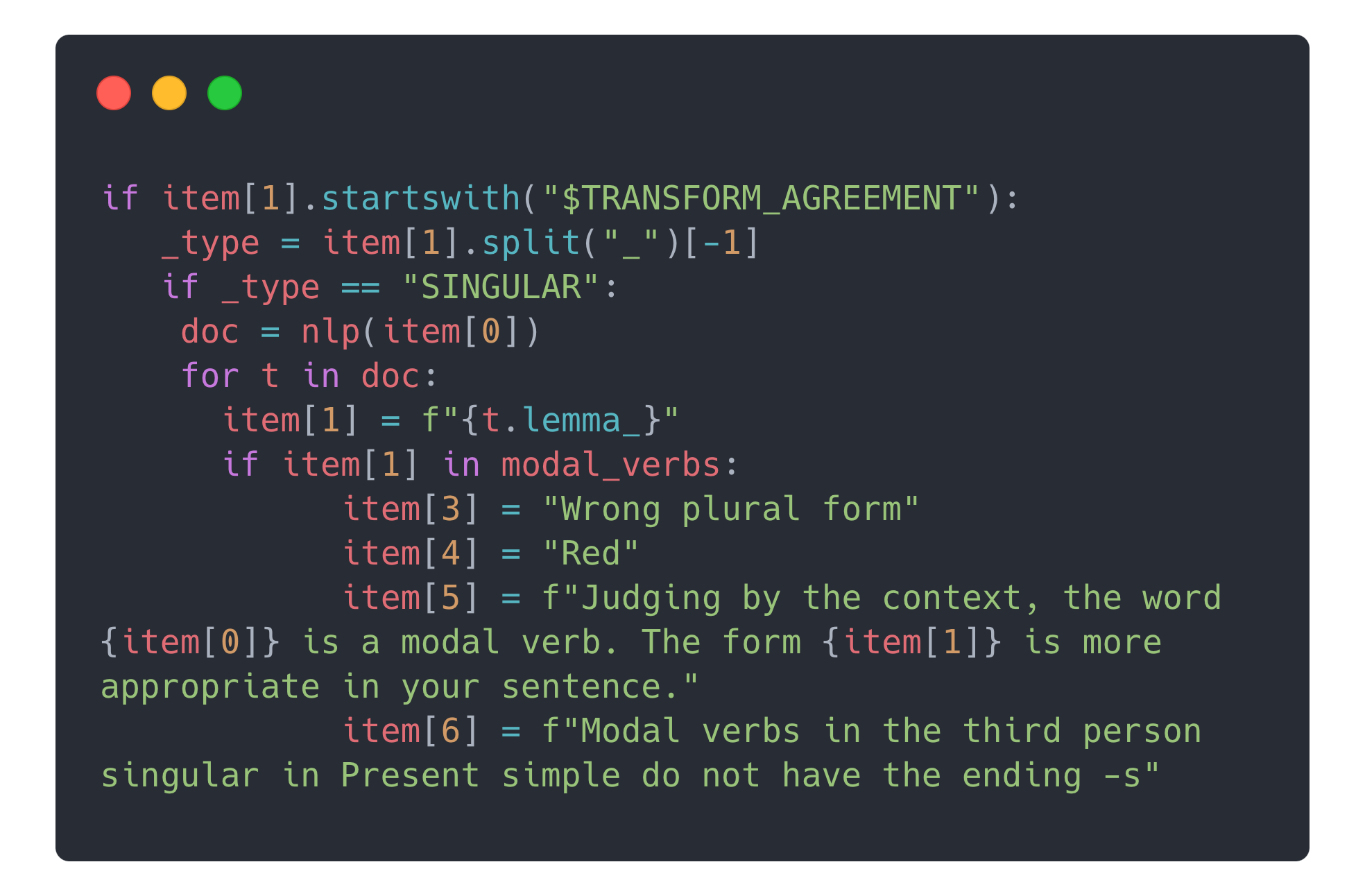
Итоговый файл состоял из нескольких десятков функций, в которых сранивались все возможные ошибки способом, похожим на код выше.
Вот ещё небольшая часть определения времени в английском:

В итоге пользовательские запросы управлялись при помощи очереди Celery и кэширования в Redis.
У нас было всего две таски для Celery, которые обрабатывались в очереди первой свободной моделью:
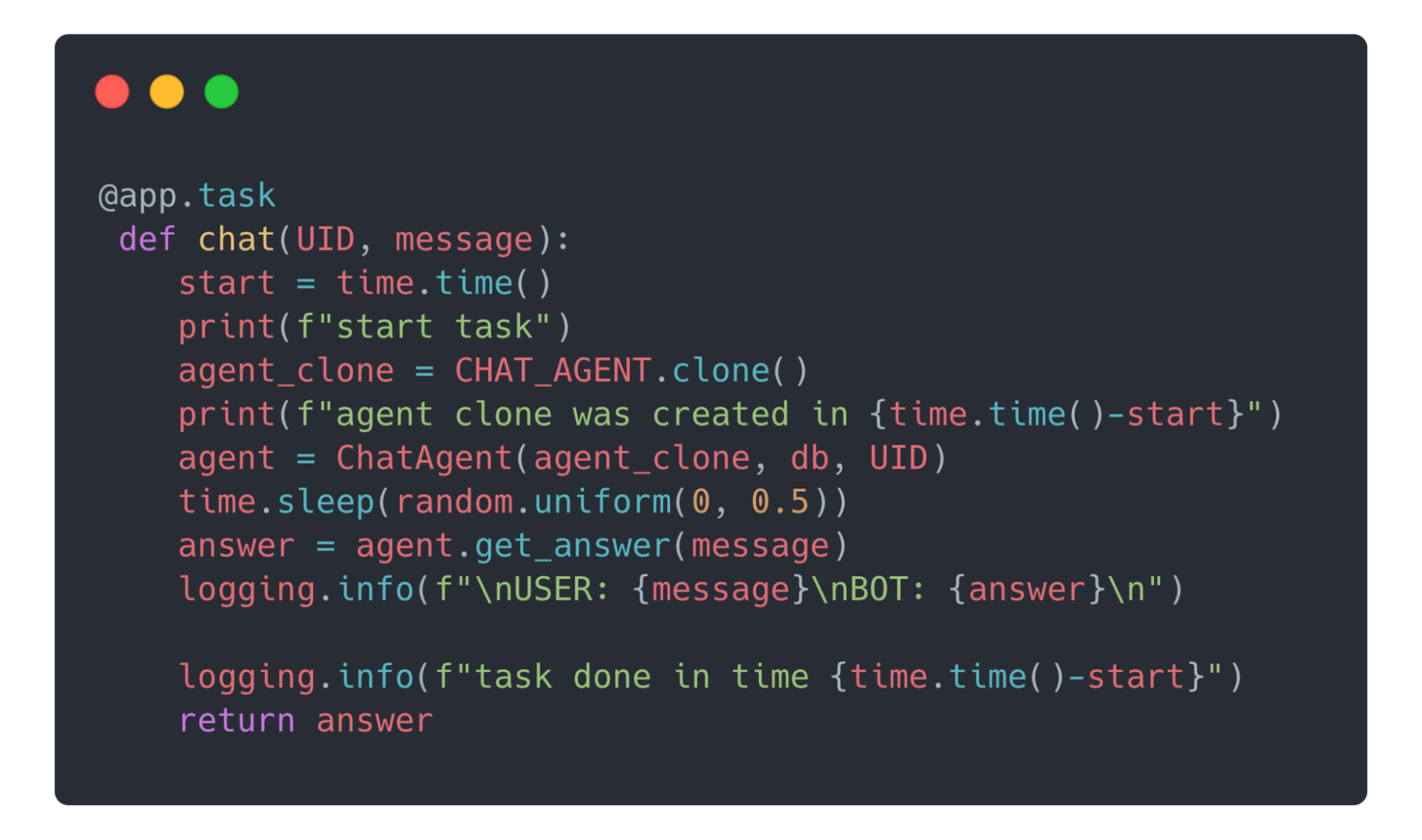
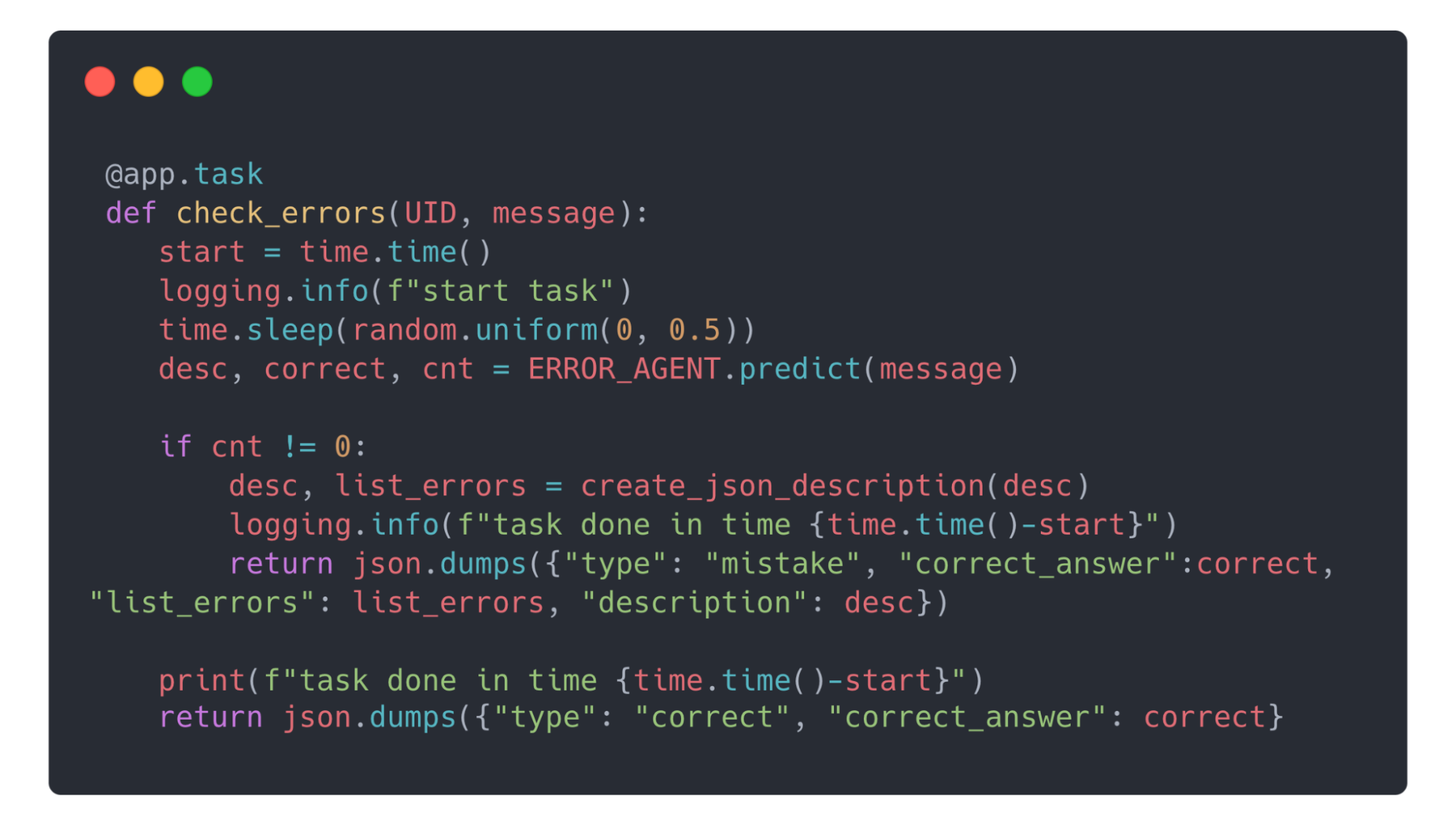
Приложение обменивается данными через API endpoints, которые подняты в отдельном worker “api”, о котором говорилось выше.
Стоит отдельно упомянуть выбор базы данных. Мы взяли MongoDB, не думаю, что в данном приложении можно было отдать предпочтение какой-то конкретной БД, но мы уже работали раньше с mongo. Существенную часть занимала история сообщений для каждого пользователя. Каждый элемент хранил в себе сообщение и его тип, в зависимости от того, кто его написал: робот или пользователь.

Вместо привычного json данные хранятся в формате для MongoDB — bson
Шаг 6. Тестирование приложения
Закономерным следующим шагом становится серия тестов, чтобы опробовать, как приложение поведет себя в жизни. Так, в нашем случае в начале были сложности с обучением модели, потому что об LLM знали только в некоторых компаниях, информации было мало. Мы решили поставить цель в виде прохождения теста Тьюринга на выборке из 100 человек. Для современных LLM это достаточно легко, но и тогда нашу модель в 70% случаев принимали за живого человека. Свои гипотезы мы тестировали через собственный сайт и подключение бота ВКонтакте.
Мы хотели сымитировать работу с живым репетитором, поэтому нам важно было проверить, что люди не раздражаются от разговоров с роботом. Так как у нас было две LLM модели (одна для обычного разговора (gpt-2), а другая для поиска ошибок), то мы достаточно быстро были удовлетворены тестами gpt-2 и перешли полноценно к улучшению другой, более сложной модели. Для ее тестирования наш методист собрала таблицу с наиболее популярными ошибками и примерами использования. На ее основе мы обучали нашу модель и дополняли примеры использования ошибок и пояснения к ним.
Шаг 7. Выбор способа монетизации
Далее предстоит определиться со способом монетизации. Сегодня на рынке их множество.
- Freemium. Предлагайте базовое приложение бесплатно и взимайте плату за премиум-функции. Эта модель эффективна для создания большой базы пользователей и последующего превращения части из них в платящих клиентов.
- In-App Purchases. Пользователи могут загрузить и использовать приложение бесплатно, но имеют возможность приобрести дополнительные функции, контент или услуги в приложении. Это часто встречается в игровых приложениях.
- Подписка. Взимание с пользователей периодической платы (ежемесячной или ежегодной) за доступ к приложению или дополнительному контенту. Эта модель популярна в приложениях, основанных на контенте, таких как новостные, музыкальные и потоковые видеосервисы.
- Реклама. Показывайте рекламу в приложении и получайте доход от кликов или показов. Такая модель может быть эффективна для приложений с большой пользовательской базой, но важно сбалансировать размещение рекламы, чтобы она не мешала пользователю.
- Монетизация данных. Если ваше приложение собирает данные (с согласия пользователя), вы можете анализировать и продавать эти данные третьим лицам, заинтересованным в получении информации о потребителях. В этом случае решающее значение имеют вопросы конфиденциальности и этики.
Основная статья расходов — это время работы ИИ на сервере, поэтому чтобы экономика проекта сходилась, нам необходимо было получать прибыль пропорциональную затратам на ИИ. Мы думали насчёт подписки, но нам показалось, что трудно будет убедить людей купить подписку, если они не смогут в течение долгого времени пользоваться приложением, чтобы вовлечься в него.
Как монетизировать данные мы не знали, да и для этого нужна гигантская база пользователей, не говоря о том, что это не совсем этично.
С рекламой чуть сложнее, например, в duolingo она есть и можно купить подписку, чтобы она исчезла, наверно поэтому она ужасно надоедливая, перекрывает весь экран и её нельзя пропустить. Мы посчитали, что для извлечения выгоды из рекламы нам нужна действительно большая база пользователей, поэтому даже если мы и захотим внедрить рекламу, то лучше сделать это потом. К тому же мы хотели, чтобы в Google Play и App Store наше приложение распространялось как детское и образовательное, а наличие рекламы этому препятствует. Как минимум, нужно было бы ее фильтровать.
Мы выбрали freemium модель, при которой у всех был доступ к приложению, чтобы мы смогли быстро вырасти в количестве пользователей. Затраты на работу модели были не слишком большими для бесплатных пользователей. Но вот тем, кто купил подписку, мы предлагаем персонализированный подход ИИ, а это выливается в дополнительные траты на серверные мощности. Также, если у вас есть распознавание речи (самые лучшие решения — платные), то тоже стоит позаботиться о подписке.
Шаг 8. Релиз приложения
Как известно, “если вам не стыдно за первую версию вашего продукта, значит, вы запустились слишком поздно”, поэтому главный совет будет следующим: обозначить в начале планирования, что конкретно войдет в ваше MVP, а именно тот функционал, который отражает ваше уникальное приложение. То есть в случае с приложением для изучения языка не стоит в первом релизе уделять внимание тонкой настройке профиля пользователя или сложным анимациям в чате, ведь ваше основное предложение — это широта возможностей ИИ.
Если вы пришли разрабатывать приложение из средних и больших компаний, то у вас наверняка был опыт очень удобных CI/CD для релиза приложений, где всё автоматизировано. Чаще всего для стартапов советуют не уделять большого внимания стороне DevOps, пайплайнам, CI/CD, и я бы согласился с этим пару лет назад, но сейчас есть отличные, почти самонастраиваемые инструменты по типу Codemagic и, вдобавок, ChatGPT прекрасно справляется с созданием конфиг-файлов, а во-вторых, на старте у вас будут частые релизы, минимум раз в неделю, поэтому я бы посоветовал потратить вначале немного времени на настройку окружения.
Обязательно нужно добавить аналитику, например, Amplitude, Google Analytics, AppMetrica, чтобы вовремя заметить тренды в вашем приложении или проблемные зоны. А также логирование ошибок, самые популярные инструменты для этого Crashlytics и Sentry.
Когда приложение уже находится в открытом доступе, главной задачей становится привлечение пользователей. На помощь придут цифровой маркетинг и SEO-стратегии для привлечения новых пользователей. Не стоит забывать и о разработке программ лояльности для удержания существующих клиентов.
Шаг 9. Построение стратегии дальнейшего развития
Выходом на рынок и даже набором популярности работа над приложением, разумеется, не заканчивается. Чтобы ваши предыдущие результаты труда не канули в лету, необходимо продолжать мыслить стратегически и видеть перспективы развития приложения: как в формате его всевозможного расширения, так и с точки зрения его усовершенствования.
С точки зрения расширения, в наши планы входит расширение списка предлагаемых языков, что позволит нам привлекать новых пользователей из различных регионов мира. Мы также стремимся расширять наше присутствие на новых рынках, особенно в странах, где доступ к качественному обучению языкам ограничен. Стоит задача и по повышению финансовой устойчивости нашего проекта: здесь помогает сотрудничество с бизнес-инкубаторами, привлечение инвесторов и партнеров.
Запланировано также сотрудничество с учебными заведениями и образовательными платформами через создание партнерских программ и B2B-платформы для взаимодействия со школами и отдельными преподавателями, которые помогут интегрировать приложение в учебные процессы и, тем самым, повысить доступность качественного образования. Учителя смогут предложить своим учениками бесплатно общаться с ИИ в приложении и анализировать их успехи через удобную платформу, а для нас это отличный способ получить детальную обратную связь.
Если же говорить об усовершенствовании, то предстоит внедрение новых функций, основанных на отзывах пользователей и последних достижениях в области ИИ. В частности, речь идет о более точном распознавании речи и персонализированных рекомендациях по обучению.
- В Госдуме хотят полностью отключить интернет детям до 14 лет - 27/03/2026 17:54
- Госдума вводит уголовную ответственность за торговлю криптовалютой - 27/03/2026 14:19
- В России создали свою PlayStation на зарубежных компонентах - 27/03/2026 13:11


